![How I Mapped My Self-Improving Claude Code System [2026]](/_next/image?url=%2Fblog%2Fself-improving-claude-code-system-hero.webp&w=3840&q=75)
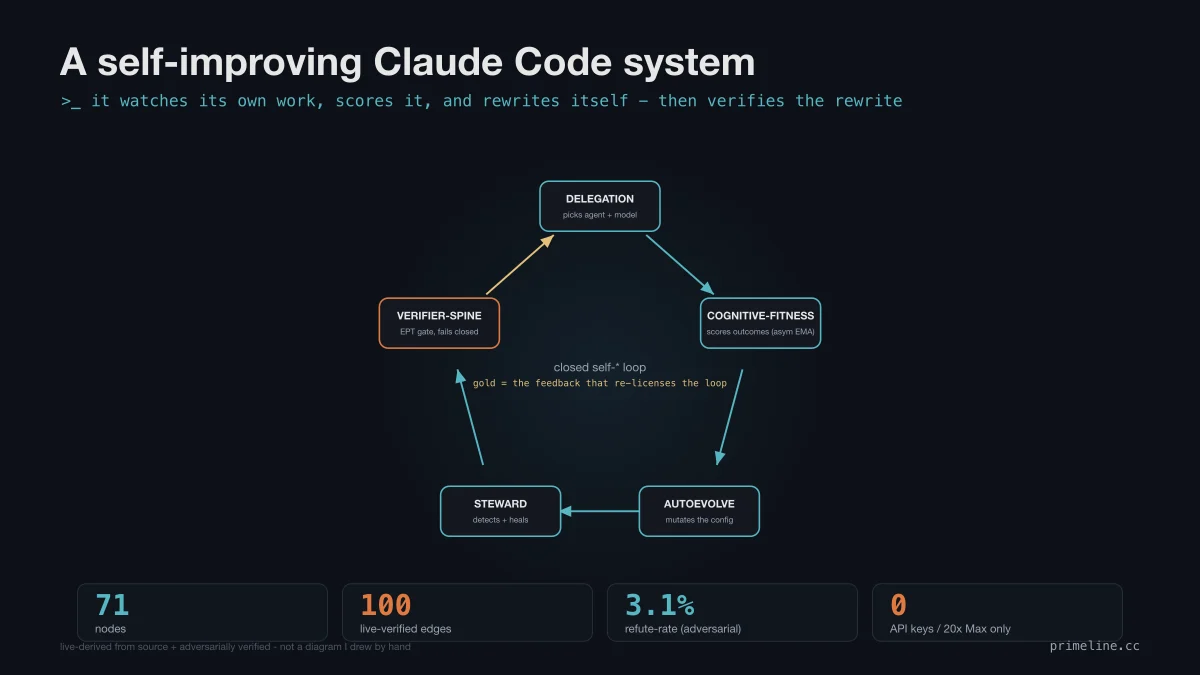
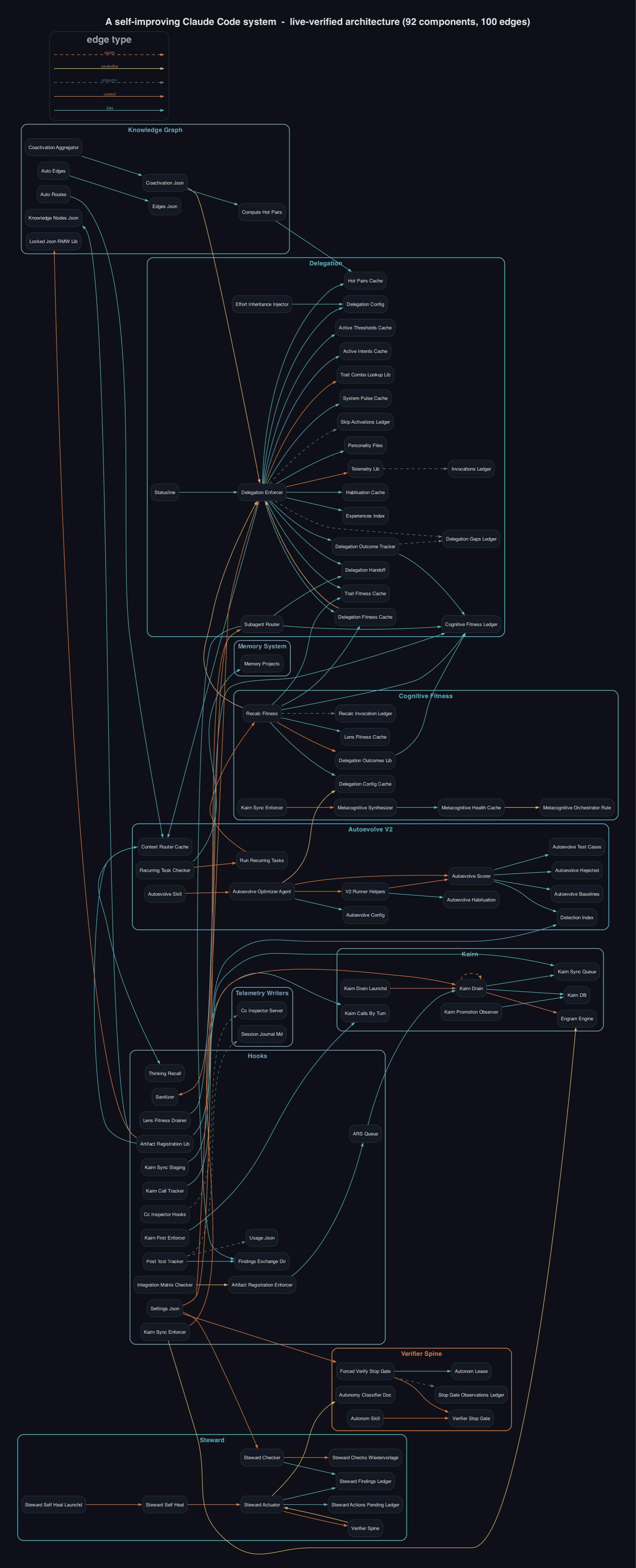
Most Claude Code setups forget everything the moment the session ends. What broke, what you decided, which agent did well, all gone. So I spent months building the opposite: a Claude Code system that watches how it works, scores its own decisions, and biases the next ones. This week I stopped trusting my own mental model of it and mapped the entire self-improving loop straight from the live code. 71 nodes, 100 edges.
The map held up better than I expected, and it surfaced a few things about my own system I had wrong. Here is what the self-improving Claude Code system actually looks like, how I proved the map is real, and which parts I am carving into Evolving Lite, my open-source Claude Code foundation.
A self-improving Claude Code system closes a loop: it logs every delegation, scores the outcomes, mutates its own routing config, and reads the new scores on the next prompt. I rebuilt the map from live code with 11 agents, then had a separate agent try to refute it. 1 edge out of 32 fell. The loop held at a 3.1% refute rate.
What is a self-improving Claude Code system?
A self-improving Claude Code system is one where the outcome of each session feeds back into how the next session behaves, with no human editing config in between. In mine that shows up as four habits, all running between my prompts.
- Self-evolving: it scores how past delegations went and biases which agent and model it picks next.
- Self-healing: a scheduled job repairs its own broken state instead of waiting for me to notice.
- Self-verifying: it refuses to let me claim a task is "done" without proof it ran and changed something real.
- Self-organizing: every file I write registers itself into a knowledge graph automatically.
The honest surprise: the self-verifying part is the one that keeps me, the human, disciplined. It blocks the "looks done" reflex more than it polices the AI. That idea has its own home in Claude Code verification, where "tests pass" stops counting as proof.
Why map it from live code instead of memory?
Because the version of a system in your head is always a few months stale. I had a maintained architecture atlas already. It was marked green. But green means "last reviewed," not "matches the code today." So instead of trusting the atlas, I re-derived the whole thing from the live source and treated every difference as a finding.
That single choice turned a documentation chore into a free audit. The fresh map disagreed with my atlas in 39 places: two entire subsystems were undocumented, one file-read was attributed to the wrong hook, and a retired data sink was still listed as active. None of that was visible from the green checkmark.
The loop that actually closes
The core claim of a self-improving system is that the loop closes. Each step has to write something the next step actually reads, or it is just a diagram with hopeful arrows. Here is the path, and every hop is backed by a real file write and read in the source.
Delegation logs every decision to a ledger. A fitness pass reads that ledger and scores each task type with an asymmetric moving average, one that drops trust faster than it grants it, so a single bad call costs more than a single good call earns. An optimizer then mutates the routing config, scores the mutation against a baseline, and keeps it only if it wins. On my next prompt, the router reads those fresh scores and shifts which agent and model it reaches for. A steward and a verifier spine gate the whole thing so nothing risky changes itself unsupervised.
That feedback edge, where yesterday's outcomes change tomorrow's routing, is the difference between a static setup and a system that learns. The session-event hooks and the memory layer it rides on already live in my open-source foundation, Evolving Lite.
This lives in primeline-ai/evolving-lite - the self-evolving Claude Code plugin. Free, MIT, no build step.
How do you verify an architecture diagram?
You do not trust a diagram you drew yourself. You make something adversarial try to break it. I split the work across independent agents so no single context could fool itself.
- 11 reader agents re-derived every connection directly from the live source.
- One separate agent then took a random sample of 32 connections and tried to refute each one by grepping the actual code.
- The bar I set in advance: if more than 10% of the sample got refuted, the map was not publishable.

One connection out of 32 got refuted, and I dropped it. 3.1%, comfortably under my 10% bar. The loop closed, and none of the 11 subsystems failed review. The refutation step is the part most "system architecture" content skips, and it is exactly the part that turns a pretty diagram into something you can actually stake a claim on. It is the same discipline I apply to self-correcting Claude Code workflows: the writer and the checker must be different.
What breaks when a system tunes itself
A self-tuning loop is not free. The two failure modes that actually bit me:
Stale provenance. The moment the system rewrites its own config, any map of it starts decaying. The fresh derivation only stayed accurate because I rebuilt it from code rather than editing notes. A self-improving system needs a self-re-deriving map, or the docs rot faster than anything else.
Trust asymmetry has to be deliberate. A symmetric average lets one lucky outcome paper over a streak of bad ones. Making the score drop faster than it climbs is what keeps the loop honest, and it has to be a designed choice, not a default. Get it backwards and the system happily reinforces its own mistakes.

Both are the kind of thing you only learn by running the loop on a real system for months, not by reading about feedback loops. That production exposure is the whole point of persistent memory across sessions.
What ships to open source
I tagged all 233 components of the loop by one question: can this leave my machine and still work? The answer split them cleanly.
- -Hardcoded paths to my filesystem
- -My private task taxonomy and config
- -Anything wired to my knowledge engine
- -Machine-specific scheduled jobs
- +The fitness scoring loop
- +The self-verify completion gate
- +The steward repair engine
- +The graph auto-registration
The reusable machinery is generic by design: it reads from repo-relative paths and carries no personal data. The personal wiring stays out. I am carving that generic core into Evolving Lite now, layer by layer, rather than dumping a private system into a public repo and calling it open source. The foundation is already there, MIT-licensed, and you can clone it today.
What I'd do differently
Two things. First, I would have built the re-derive-from-code step before the atlas, not after. The atlas felt like the source of truth and it quietly was not. Second, I would tag portability at the moment a component is created, not in one big pass at the end. Deciding "generic or personal" 233 times in a row is the kind of work you put off, and putting it off is exactly why the open-source carve took this long to even start.
If you want the foundation this is built on, the event hooks and the memory layer live in Evolving Lite on GitHub. Clone it and the session memory plus auto-learning from your corrections run today; the fitness loop and the verify gate land as the carve progresses. Build systems, not sessions.
![The Anatomy of My Claude Code System [2026]](/_next/image?url=%2Fblog%2Fclaude-code-system-anatomy-hero.webp&w=3840&q=75)
![How to Build a Claude Code Plugin: Real Example [2026]](/_next/image?url=%2Fblog%2Fclaude-code-plugins-hero.webp&w=3840&q=75)
